Building a Virtual Filesystem for Efficient Documentation Retrieval
By Dens Sumesh
AI Summary
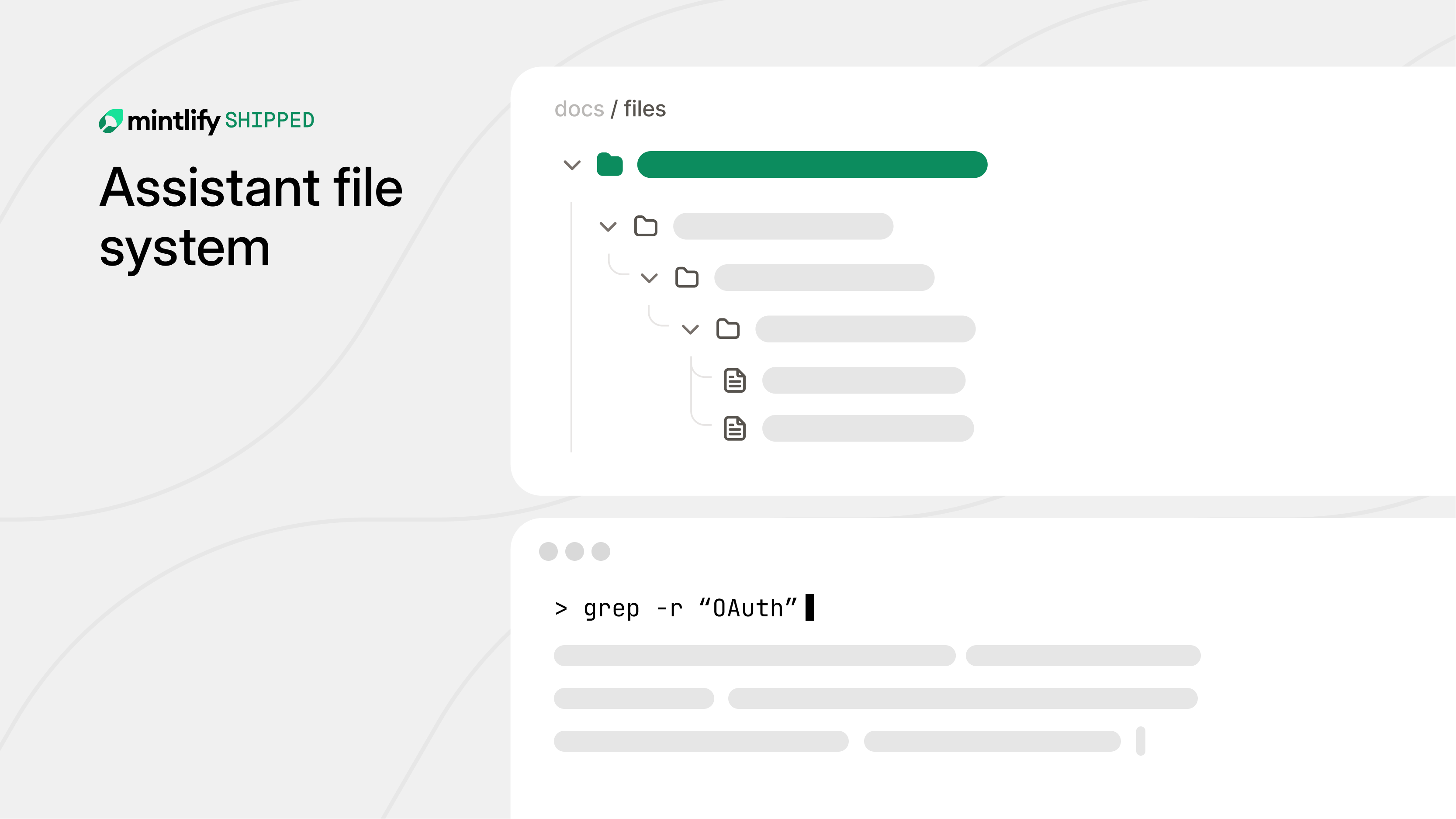
To enhance our assistant's ability to navigate documentation like a codebase, we developed ChromaFs, a virtual filesystem that mimics a real one without the associated costs and latency. Traditional methods using sandboxes and real filesystems were too slow and expensive, especially given our high volume of 850,000 monthly conversations. By leveraging our existing Chroma database, we created a system where UNIX commands are translated into database queries, drastically reducing session creation time from 46 seconds to 100 milliseconds and eliminating additional compute costs.
ChromaFs is built on just-bash by Vercel Labs, which supports essential UNIX commands. It uses a gzipped JSON document to bootstrap the directory tree, allowing commands like ls, cd, and find to resolve in-memory without network calls. This setup also includes access control, filtering files based on user permissions, which would be cumbersome in a real filesystem.
Pages are stored in chunks for efficient retrieval, and ChromaFs reassembles them on demand. For large files, lazy pointers are used to fetch content only when needed. The system is read-only, preventing any data mutations and ensuring stateless operation.
ChromaFs efficiently handles grep operations by using Chroma as a filter to identify potential matches, caching results in Redis, and executing fine-grained searches in-memory. This approach allows for fast recursive queries without network delays.
Overall, ChromaFs provides a scalable and cost-effective solution for documentation retrieval, supporting hundreds of thousands of users daily without requiring new infrastructure.
Key Concepts
A virtual filesystem is an abstraction layer that allows software to interact with data storage as if it were a traditional filesystem, without the need for physical storage structures. It provides an interface for file operations like reading and writing, while the actual data management is handled differently under the hood.
Database query translation involves converting commands or requests into queries that a database can understand and execute. This process allows for efficient data retrieval and manipulation by leveraging the database's indexing and search capabilities.
Category
TechnologyMore on Discover
Summarized by Mente
Save any article, video, or tweet. AI summarizes it, finds connections, and creates your to-do list.
Start free, no credit card