Exploring the 80386 Memory Pipeline in FPGA Implementation
AI Summary
I've successfully developed an FPGA 386 core that boots DOS, runs applications like Norton Commander, and even plays Doom at 75 MHz on a DE10-Nano. With the core now capable of running real software, it's time to delve into the 80386's memory pipeline, a critical component for performance. The 80386's 32-bit Protected Mode was revolutionary, and while previous discussions focused on virtual-memory protection, this time I explore the microarchitecture of the memory access pipeline, address translation efficiency, microcode's role, and RTL timing.
On paper, x86 virtual memory management seems costly, involving address calculations, segment relocations, TLB lookups, and page-table reads. Yet, Intel's 1986 paper by Jim Slager reveals that the common-case address path completes in about 1.5 clocks. This efficiency stems from a carefully overlapped memory pipeline using pre-calculation, pipelining, and parallelism.
## Microcode and Memory Access
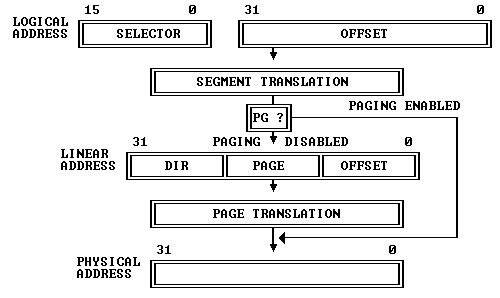
The 80386 transforms logical addresses into physical ones in two steps: segment and page translation. The microcode for memory operations, such as ADD [BX+4], 8, involves reading, modifying, and writing back memory. Key operations include RD for reads, WR for writes, and DLY for delays until memory catches up. These operations must be efficient to prevent system slowdowns.
## Efficient Segmentation
Segmentation is mandatory in both protected and real modes. While it could be costly, optimizations like cached segment states prevent repeated descriptor lookups. When a selector is loaded, the processor caches the descriptor's base, limit, and attributes, avoiding constant table consultations. This design choice allows segmentation to be treated as local state, not table-walking.
## Parallel Relocation and Limit Checking
To form a linear address, the processor adds the segment base to the effective address while checking limits in parallel. This approach avoids waiting for the final linear address and uses efficient arithmetic paths to ensure performance.
## Early Start Optimization
The 80386 employs an 'Early Start' technique where address-related work begins in the last cycle of the previous instruction, overlapping with writeback. This optimization, though complex, improves performance by about 9% but also introduces potential bugs, such as the POPAD bug.
## Paging and Bus Interface
Paging, crucial for performance, is part of the fast path. On a TLB hit, translation fits into the memory pipeline. The 80386 uses a non-multiplexed address/data bus, allowing efficient address pipelining. The Intel 82385 cache controller enhances performance by managing cache hits and misses, significantly boosting speed.
## FPGA Implementation
Mapping the 80386 memory pipeline to an FPGA involves challenges like asynchronous vs. synchronous logic. While the original 80386 used latches, modern FPGAs use flip-flops, requiring careful register placement for optimal performance. The FPGA design includes a 16 KB instruction cache and a 16 KB data cache for efficient memory access.
The 80386's memory pipeline, with its latency-hiding techniques, made it a practical foundation for PC operating systems, performing close to physical memory. Future discussions will cover instruction prefetching, task switching, and more.
Key Concepts
A memory pipeline is a series of steps that a processor uses to access and manage memory efficiently. It involves overlapping operations like address translation, data fetching, and execution to minimize latency and improve performance.
Segmentation is a memory management technique where memory is divided into segments, each with a base address and a limit. It allows for efficient memory access and protection by isolating different parts of a program.
Category
EngineeringMore on Discover
Summarized by Mente
Save any article, video, or tweet. AI summarizes it, finds connections, and creates your to-do list.
Start free, no credit card