Understanding Modern Microprocessors: From Pipelining to Multi-Core
By — John Sladek
AI Summary
In the world of modern microprocessors, performance isn't just about clock speed. It's about how efficiently a processor can execute instructions per cycle. This efficiency is achieved through techniques like pipelining, where multiple instructions are processed simultaneously at different stages, akin to an assembly line. This allows processors to complete an instruction per cycle, significantly boosting performance without increasing clock speed.
## Pipelining and Superpipelining
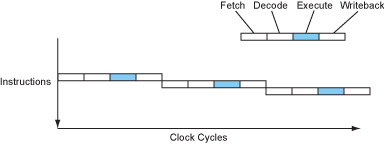
Pipelining involves overlapping the execution stages of instructions, allowing a processor to handle multiple instructions at once. Early RISC processors like the MIPS R2000 used simple pipelines, which were more efficient than the complex instruction sets of CISC processors. Superpipelining takes this further by subdividing pipeline stages, enabling higher clock speeds and more instructions per second.
## Superscalar and VLIW Architectures
Superscalar architectures enhance performance by executing multiple instructions in parallel across different functional units. This requires sophisticated fetch and decode stages to manage multiple instruction streams. VLIW (Very Long Instruction Word) architectures simplify this by grouping instructions for parallel execution, reducing the need for complex dispatch logic.
## Instruction Dependencies and Branch Prediction
Instruction dependencies can stall pipelines, as some instructions rely on the results of others. Branch prediction helps mitigate this by guessing the outcome of conditional instructions to keep the pipeline filled. Modern processors use dynamic branch prediction to improve accuracy, but mispredictions can still incur significant penalties.
## Out-of-Order Execution and Register Renaming
Out-of-order execution allows processors to rearrange instructions dynamically to optimize pipeline use, while register renaming helps manage dependencies by using a larger set of physical registers. This complexity increases power consumption and design difficulty but can significantly boost performance.
## The Power and ILP Walls
Processors face limitations in clock speed due to power consumption and heat, known as the power wall. Additionally, the ILP (Instruction-Level Parallelism) wall limits performance gains from parallel execution, as most programs don't naturally exhibit high parallelism.
## Multi-Core and SMT
To overcome these limitations, processors have shifted towards multi-core designs and simultaneous multi-threading (SMT), which allow multiple threads to execute on a single core. This approach increases throughput without the need for higher clock speeds.
## Memory Hierarchy and Caches
The memory wall remains a challenge, as memory access times lag behind processor speeds. Caches mitigate this by storing frequently accessed data close to the processor, significantly reducing access times. The memory hierarchy, from L1 caches to main memory, balances speed and size to optimize performance.
## Data Parallelism and SIMD
SIMD (Single Instruction, Multiple Data) instructions exploit data parallelism by applying a single operation to multiple data points simultaneously. This is particularly effective in multimedia and scientific applications, providing substantial speedups.
## The Future of Processor Design
As processors evolve, the focus is on balancing core complexity, power efficiency, and parallelism. Hybrid designs combining large, powerful cores with smaller, efficient ones offer a promising path forward, maximizing performance across a range of applications.
Key Concepts
Pipelining is a technique used in microprocessors where multiple instruction stages are overlapped to improve execution efficiency. It allows for the simultaneous processing of several instructions, each at a different stage of execution.
Instruction-Level Parallelism refers to the ability of a processor to execute multiple instructions simultaneously. This is achieved through techniques like pipelining, superscalar execution, and out-of-order execution.
Branch prediction is a technique used in processors to guess the outcome of conditional instructions to maintain pipeline efficiency. It helps reduce the performance penalties associated with branch instructions.
Category
TechnologyOriginal source
https://www.lighterra.com/papers/modernmicroprocessors/More on Discover
Summarized by Mente
Save any article, video, or tweet. AI summarizes it, finds connections, and creates your to-do list.
Start free, no credit card