Introducing Ternary Bonsai: Efficient Language Models with High Accuracy
AI Summary
Today marks the unveiling of Ternary Bonsai, a cutting-edge family of 1.58-bit language models that strike a balance between stringent memory constraints and high accuracy demands. Building on the foundation of the 1-bit Bonsai models, which demonstrated that extreme compression could yield commercially viable language models, Ternary Bonsai offers a modest increase in size for significant performance gains. Available in three sizes—8B, 4B, and 1.7B parameters—these models utilize ternary weights {-1, 0, +1} to achieve a memory footprint approximately nine times smaller than standard 16-bit models, while outperforming most competitors in their parameter classes on standard benchmarks.
## A True Ternary Model
Ternary Bonsai employs a 1.58-bit representation throughout its entire network architecture, ensuring consistency across embeddings, attention layers, MLPs, and the LM head. The models use a group-wise quantization scheme where each weight is restricted to one of three values: {-s, 0, +s}, encoded as (-1, 0, +1) using 1.58 bits per weight, along with a shared FP16 scale factor for each group of 128 weights.
## Benchmark Performance
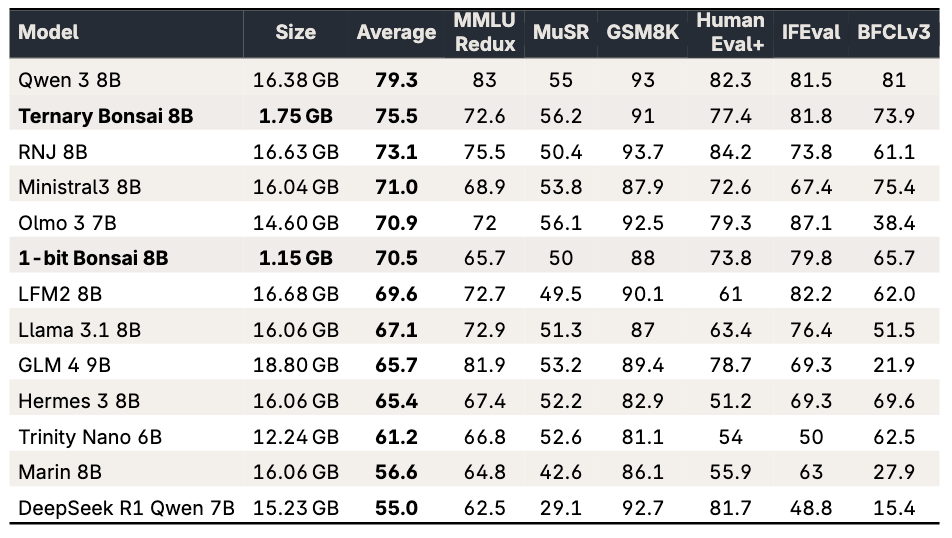
The Ternary Bonsai 8B model scores an average of 75.5 across benchmarks, outperforming the 1-bit Bonsai 8B by 5 points, while requiring only 600MB more memory. Despite being 9-10 times smaller, it surpasses most peers, trailing only behind Qwen3 8B. The model demonstrates broad performance gains across various benchmarks such as MMLU Redux, MuSR, GSM8K, HumanEval+, IFEval, and BFCLv3.
## Extending the Pareto Frontier
The Ternary Bonsai models extend the Pareto frontier established by the 1-bit Bonsai models, offering a new tradeoff between memory footprint and model strength. While the 1-bit models remain ideal for scenarios prioritizing minimal footprint, Ternary Bonsai provides an alternative for settings where a slight memory increase can justify a stronger model. The 1.7B, 4B, and 8B variants offer flexibility across multiple deployment tiers.
## Throughput and Energy Efficiency
These models deliver impressive throughput and energy efficiency. On the M4 Pro, Ternary Bonsai 8B operates at 82 tokens per second, about five times faster than a 16-bit 8B model, and at 27 tokens per second on the iPhone 17 Pro Max. They consume significantly less energy, achieving 3-4 times better energy efficiency compared to their 16-bit counterparts.
## Platform Coverage
Ternary Bonsai models run natively on Apple devices via MLX, with model weights available under the Apache 2.0 License. PrismML, founded by Caltech researchers with support from Khosla Ventures, Cerberus, and Google, continues to tackle the challenge of compressing neural networks without compromising reasoning ability. For those interested in contributing to the next generation of AI, opportunities are available on their careers page.
Key Concepts
Ternary quantization is a technique used in machine learning to reduce the precision of weights in a neural network to three possible values, typically {-1, 0, +1}. This reduces the memory footprint and computational requirements while attempting to maintain model performance.
Memory efficiency in computing refers to the ability to use memory resources in a way that maximizes performance while minimizing waste. In the context of machine learning, it often involves reducing the size of models without sacrificing accuracy.
Category
AIOriginal source
https://prismml.com/news/ternary-bonsaiMore on Discover
Summarized by Mente
Save any article, video, or tweet. AI summarizes it, finds connections, and creates your to-do list.
Start free, no credit card