Understanding KL-Divergence: A Comprehensive Intuition Guide
AI Summary
KL-divergence is a fundamental concept in information theory and machine learning, often misunderstood due to its non-symmetric nature and unbounded properties. To demystify it, I explore various intuitive frameworks that illuminate its essence.
## Expected Surprise
Imagine you're observing data under a false belief about its distribution. KL-divergence measures how much more surprised you'd be compared to knowing the true distribution. This surprise is tied to the probability of events; lower probabilities mean higher surprise. The divergence quantifies the difference in expected surprise between your model and reality, explaining its asymmetry: it 'blows up' when your model assigns low probability to frequent events.
## Hypothesis Testing
In hypothesis testing, KL-divergence represents the expected evidence for one hypothesis over another when the null hypothesis is true. It quantifies how distinguishable two hypotheses are based on observed data. If two distributions are similar, distinguishing between them is challenging, reflecting in a lower KL-divergence.
## Maximum Likelihood Estimation (MLE)
MLE involves finding parameters that maximize the likelihood of observed data. By minimizing the cross-entropy between empirical and model distributions, we effectively minimize KL-divergence. A large divergence suggests a poor model fit, indicating the model's inadequacy in representing the true data distribution.
## Suboptimal Coding
In information theory, optimal coding minimizes the expected message length. If you design a code based on an incorrect distribution, KL-divergence measures the extra bits needed compared to an optimal code. It highlights inefficiencies in encoding when the assumed distribution deviates from reality.
## Gambling Games
KL-divergence also applies to gambling scenarios. If you know the true probabilities of a game but the house doesn't, the divergence quantifies potential winnings. The asymmetry arises because the house's incorrect odds can be exploited when they overpay for certain outcomes.
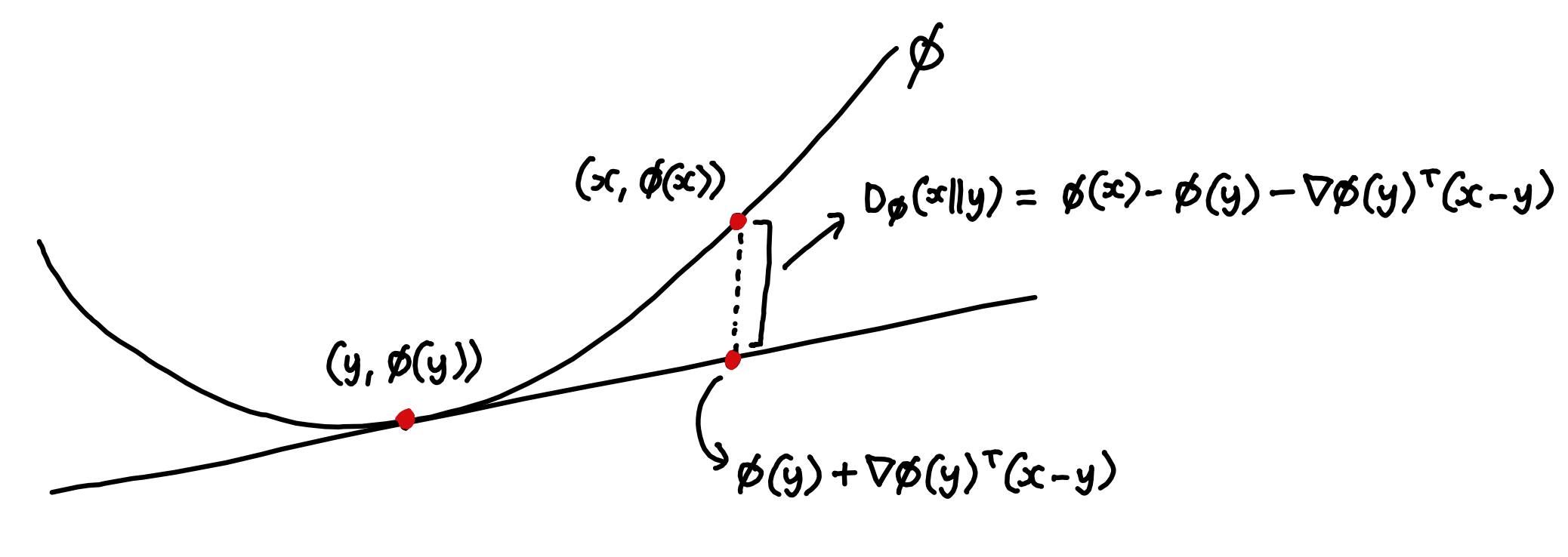
## Bregman Divergence
Bregman divergence offers another perspective, linking convex functions to divergence measures. It shows how KL-divergence naturally emerges when entropy is used to measure a distribution's 'distance from zero'. This framing underscores the importance of choosing appropriate divergence measures based on the context.
In essence, KL-divergence is a versatile tool for measuring how much a model deviates from the true distribution. It captures the inefficiencies, surprises, and potential gains that arise from such deviations, offering a rich understanding of model accuracy and information theory.
Key Concepts
KL-divergence is a measure of how one probability distribution diverges from a second, expected probability distribution. It quantifies the inefficiency of assuming that the distribution is Q when the true distribution is P.
Expected surprise quantifies how much more surprised an observer would be when events occur under an incorrect probability model compared to the true model.
Hypothesis testing is a statistical method that uses sample data to evaluate a hypothesis about a population parameter. It often involves comparing two hypotheses: the null and the alternative.
Category
MathematicsOriginal source
https://www.perfectlynormal.co.uk/blog-kl-divergenceMore on Discover
Summarized by Mente
Save any article, video, or tweet. AI summarizes it, finds connections, and creates your to-do list.
Start free, no credit card